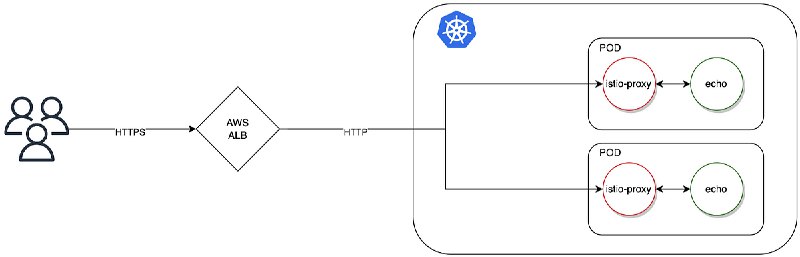
## Intermittent 503 Error Analysis
### Root Cause
You have a connection timeout mismatch:
- Spring Gateway maxIdle: 59 seconds
- ALB idle timeout: 60 seconds
### Why This Causes 503
Timeline of the problem:
1. At 59s: Spring Gateway closes the idle connection
2. At 60s: ALB still thinks the connection is open
3. New request arrives → ALB tries to use the closed connection
4. Result: 503 Service Unavailable
### The Rule
Backend timeout must be GREATER than load balancer timeout
### Solution
Option 1: Increase Spring Gateway timeout (Recommended)
Option 2: Decrease ALB timeout
### Why This Happens
- Occurs during low traffic (connections stay idle longer)
- Creates a 1-second race condition (59s-60s window)
- ALB reuses a connection that Spring already closed
### Validation from AWS
AWS documentation confirms: backend keep-alive timeout should be greater than the load balancer's idle timeout [AWS re:Post](https://repost.aws/knowledge-center/eks-http-504-errors) to prevent exactly this issue.
Your diagnosis is 100% correct! This is a classic connection pool timing problem.
### Root Cause
You have a connection timeout mismatch:
- Spring Gateway maxIdle: 59 seconds
- ALB idle timeout: 60 seconds
### Why This Causes 503
Timeline of the problem:
1. At 59s: Spring Gateway closes the idle connection
2. At 60s: ALB still thinks the connection is open
3. New request arrives → ALB tries to use the closed connection
4. Result: 503 Service Unavailable
### The Rule
Backend timeout must be GREATER than load balancer timeout
✗ Wrong: Gateway 59s < ALB 60s → 503 errors
✓ Correct: Gateway 65s > ALB 60s → No errors### Solution
Option 1: Increase Spring Gateway timeout (Recommended)
spring:
cloud:
gateway:
httpclient:
pool:
max-idle-time: 65s # Must be > 60sOption 2: Decrease ALB timeout
# Set ALB to 55 seconds
alb.ingress.kubernetes.io/load-balancer-attributes:
idle_timeout.timeout_seconds=55### Why This Happens
- Occurs during low traffic (connections stay idle longer)
- Creates a 1-second race condition (59s-60s window)
- ALB reuses a connection that Spring already closed
### Validation from AWS
AWS documentation confirms: backend keep-alive timeout should be greater than the load balancer's idle timeout [AWS re:Post](https://repost.aws/knowledge-center/eks-http-504-errors) to prevent exactly this issue.
Your diagnosis is 100% correct! This is a classic connection pool timing problem.