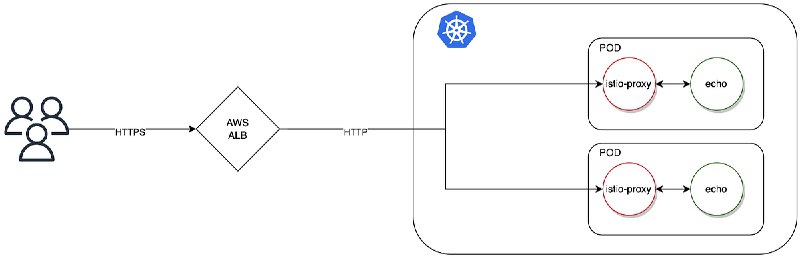
Read “AWS ALB returns 503 for Istio enabled pods“ by Jacek Domagalski on Medium: https://domagalski-j.medium.com/aws-alb-returns-503-for-istio-enabled-pods-a6942383143c
acshame
-
- Read “Spring Cloud Gateway and Connection Leak“ by yongjoon on Medium: https://medium.com/@avocadi/spring-cloud-gateway-and-connection-leak-5831293ef527
-
- 估计很多人在等我的技术复盘,那么聊聊
开宗明义,我们应该是目前 All in Cloudflare 公司中这次事故中恢复的最快的一批
Cloudflare 这次的事故其实应该分为两个 Part 来说,DNS 面和数据面。这次炸的实际上是数据面
早在10月20多号,Cloudflare 因为机房在维护而导致流量切换的时候,我们的跨洋访问线路就出现了问题。当时讨论后,我和同事达成一致,决定开始着手将我们的 DNS 和 CDN 分离开来,切换到不同的 vendor 上。
对我们来说 CDN 是 Cloudfront我们在某次冒烟的1h内完成了一条关键链路的迁移。实际上这为我们今天的处理奠定了一个良好的基础
而在本周一,我完成了我们核心域名 Cloudflare 上 DNS record 的 terraform 化。
所以回到事故本身,不同于 AWS 事故我们能做的会相对更少,而 Cloudflare 事故中,我们能尝试做的事情很多。所以我们按照预案,有 Plan A/B
A. DNS 和 CDN 双切
B. 在 Cloudflare API 面恢复后仅切换 CDN
我们最后得出结论,选择 Plan B。当然我们也在 Route53 上做好了 Plan A 的准备
而之前准备的 Terraform 实际上在此时帮上了忙,在 Cloudflare API 恢复的第一时间,实际上 Dashboard 和 2FA 等 Auth 还是 failure 的状态。Terraform 帮助我们第一时间完成了切换。同时同事能帮我进行很严谨的 cross check。
分享一些能高效处理事故的 tips 吧
1. 及时拉会,我们事故处理会是一个全员 open 的会
2. 需要有人来承担一号位的职责,负责控场
3. 越忙越容易出错,所有变更一定要同步+cross check,我自己习惯是两次确认“同步:我将变更xx,内容为xxx,请xx帮我确认”,“确认执行,请xx协助验证”
4. 设置关键的时间点,并定时更新时间点。比如我们最开始切换 CDN 时间点定为 , 然后因为临时原因延后。而我们最开始对外恢复公告的时间点定为 UTC+8 ,然后结束前半小时我 reset timer ,定位 UTC+8 。明确的时间点能协助同事更明确知道我们当前在做什么,需要做什么,以及下一步做什么
说实话今晚再一次感受到了有一群很棒的同事是很爽的一件事。我们共同决策,执行指令,处理 corner case,制定接下来的 48h 的 action item,乃至考虑要不要升级数据库(不是(。
期间我有很多在我规划的预案中没有 cover 的部分,而每个同事都在帮助我查漏补缺,这无疑是非常爽的一件事。
如同我们结束了 5h 的全程 follow up 的事故复盘会后,CTO 发的全员感谢信一样“无论是在事先预案和技术实施文档上,还是在应急决策的果断和集体决策(快速信息补齐,临时分工合作,互相 review 找 bug),体现出来的专业性,技术能力,合作精神,都比之前上了不小的台阶”
是的,每个良好的团队,都会随着每一次事故而成长。
最后打个小广告,鄙司目前诚招前/后端/推荐算法/推理加速/infra 等方向的人,如果你想和我们一起成长,欢迎聊聊 - 这个真的得第一时间品尝,真正的多 agent 协同进行完整的开发流程,不仅仅是写代码,还有浏览器操作、屏幕读取、自动化测试…而且是一个 dedicated agent workbench, not just a plugin of IDEs
https://antigravity.google/ - #系统编程
《The Life of a Packet in the Linux kernel》,Linux中数据包的一生。
这篇文章以curl 访问一个网站为例,介绍了数据包在Linux系统中从应用程序发送到接收的完整路径。包括Linux网络数据包从send()到recv()的九大核心步骤,涵盖套接字、TCP/IP协议栈、路由、ARP、队列管理、DMA、NAPI、防火墙、NAT等关键机制,结合命令实践,帮助开发者理解底层网络通信原理,可以看作是Linux网络栈入门指南。 - 转推了前端大法师 antfu 的一篇推文,关于自信力的。
其实我时常觉得自己没有自信来着,一方面是见贤思齐,另一方面自己并不是一个精力满满的人。
不过这样的我也足够做一些自己喜欢的事情,要加油!
https://x.com/repsiace/status/1987373777043529762 -
- 当接到一个新任务时,尤其是在会议或讨论后,大脑会装满各种相关的上下文信息,就像缓存一样。如果你此刻觉得自己对任务很清楚了,就应该立刻开始执行,而不是把它加入任务清单,安排到所谓的"特定时间"再做。
这是因为,大脑此刻的清晰感来源于这些充足的上下文,而这些信息会随时间快速衰减。虽然你可能通过笔记(如任务概述或会议纪要)记录了这些信息的线索,但它们只是高度压缩的索引。重新"解压"和展开这些索引同样耗时。很多时候,我们大量的时间恰恰耗费在重新理解这些上下文线索上。
所以,我们应该趁着大脑对任务认知清晰、解决方案呼之欲出的状态,立刻开始实现。这相当于把这件事所需的信息"转储"(dump)出来,固化为实际的成果,从而减轻大脑的负担。
其实,完成一件事情的核心框架所需的速度是很快的。如果你觉得时间不够,哪怕只是写写伪代码、定好函数名和调用方式,甚至用口述(语音输入提示词给AI)来勾勒出执行路径,也算一个开始。
从熵增的逻辑来理解也很清楚。如果推迟执行,任务的"熵"会越来越高。未来要降低这个熵,所需花费的时间和精力,等于要重来一遍。但只要任务开始了,它需要排解的"熵"就会减少。当下一次继续时,需要加载到大脑"内存"中的数据也会减少。因为任务已经变得有条理,只需按需加载即可。这就像一个游戏,初始状态是加载整个大地图,但当框架搭好、脉络清晰后,下次只需加载某个特定关卡,所需的"内存"自然就少了。
所以,当你对一件事很清楚时,不要犹豫,立刻去做。不要延后,不要拖延。这(或许)是唯一不能拖延的事情。你可以拖延其他事情,那些拖延(相比之下)或许没有代价。但是,当你知道一件事情该怎么做之后,每拖延一秒,你都必须为之付出代价——也许是双倍的时间。
so do it, do it immediately when you clearly know what to do - 发票抬头 北京外企人力资源服务有限公司
公司税号 9111010574470043X2 -
- 如果对 debug 感兴趣,大家可以依次看我心目中最厉害的 debugger 的三个视频和一个播客,能学到非常多的东西:
1. Real World Debugging with eBPF
https://www.youtube.com/watch?v=nggZEwGLC-Q
2. eBPF for Python Troubleshooting
https://m.bilibili.com/video/BV1bJz9YTEGJ
3. gdb -p $(pidof python)
https://bilibili.com/video/BV121Wnz1ELm
4. 播客《和 Gray 聊聊那些年遇到的神奇 Bug》
https://pythonhunter.org/episodes/ep35 - 5. 其他动态
1 Qwen3-Max-Thinking 早期预览版发布
2 Agent HQ 将 GitHub 转变为一个开放的生态系统,将所有AI 编程助手整合到GitHub,像管理团队一样管理多个 AI 代理。从规划到写代码、再到审查与部署,将代理原生集成到 GitHub 工作流程中。Mission Control 任务控制中心,贯穿 GitHub、VS Code、移动设备和 CLI 的统一界面,可以指挥、监控和管理每一项 AI 驱动的任务。还能接入 Slack、Linear、Jira、Teams 等工具。 原文地址:github.blog/news-insights/company-news/welcome-home-agents
3 Cursor 2.0 正式发布全新”自研“AI模型 Composer 1 alpha,特点就是速度快(已有twiter大佬确认此模型来自开源的deepseek模型,证据是使用了相同的分词器Tokenizer)
4 智源研究院开源多模态世界模型,Emu3.5、Emu3.5-Image、Emu3.5-VisionTokenizer 一个不再满足于看图说话或听指令画画,而是试图通过“ binge-watching(刷剧)”海量网络视频来理解并模拟我们这个世界的“世界学习者”。致力于将视觉和文字真正融会贯通。 模型地址:huggingface.co/collections/BAAI/emu35 论文地址:arxiv.org/pdf/2510.26583
5 通义开源 UI-Ins-7B/32B 模型,核心能力是将自然语言指令映射到可操作的UI元素。 模型涌现推理能力,能够在推理阶段选择性地组合和合成新的指令路径。
▪ 看外观 (Appearance): “点那个红色的X。”(描述目标的视觉特征)
▪ 说功能 (Functionality): “关闭这个文件管理器。”(描述目标的功能)
▪ 指方位 (Location): “点一下右上角的按钮。”(描述目标的相对位置)
▪ 谈意图 (Intent): “我想把这个屏幕弄掉。”(描述最终想要达成的目的)
6
模型地址:huggingface.co/Tongyi-MiA/UI-Ins-7B huggingface.co/Tongyi-MiA/UI-Ins-32B 论文地址:arxiv.org/pdf/2510.20286
7 100B 的 diffusion 文本模型 LLaDA2.0-flash-preview-100B-A6B!MoE 架构! 上下文大小4K,MMLU-Pro (测大模型知识能力的) 分数,LLaDA2.0-flash-preview 是 66.16,而 GPT-4-Turbo 是 63.71,性能还是比较有限的。 模型地址:huggingface.co/inclusionAI/LLaDA2.0-flash-preview
8 Neo 家用机器人预购(预购价是两万美金)宣发, 2026 年开始在美国交付。 争议点在目前还是远程摇控操做的。总感觉比 马斯克的 Figure 03 差一些。
官方号称能做家务,如扫地吸尘、端盘子洗碗、叠衣服收纳、搬东西浇花;智能陪伴,比如聊天互动、识别物品、给出建议,接待客人等;并且能自主学习和充电。
9 SoulX-Podcast 开源TTS模型,参数1.7B,专为播客风格的多轮、多说话人对话语音生成而设计。支持普通话、英语以及多种汉语方言,包括川话、河南话和粤语。能够连续生成超过 90 分钟的对话,且说话人音色稳定,语调过渡流畅。此外,说话人能够根据上下文调整韵律,随着对话的进行自然地改变节奏和语调。 Repo地址:github.com/Soul-AILab/SoulX-Podcast 模型地址:huggingface.co/collections/Soul-AILab/soulx-podcast 论文地址:arxiv.org/abs/2510.23541 试听地址:soul-ailab.github.io/soulx-podcast
Github Repos Recommend
1 LLM 炒币 nofx nof1.ai 的开源复刻版,感兴趣的小伙伴可自行部署。期待一个 rockalpha.rockflow.ai A股复刻版。 Repo 地址:github.com/NoFxAiOS/nofx
2 Text2SQL Vanna 一款开源的 Python 框架,利用检索增强生成(RAG)技术,把自然语言自动转成SQL语句。
▪ 支持训练专属的问答模型
▪ 直接执行生成的SQL,返回查询结果和数据可视化图表
▪ 支持PostgreSQL、MySQL、Oracle等数据库
▪ 兼容OpenAI、Anthropic等多种LLM
▪ 使用灵活且安全,数据不会外泄,所有SQL都在本地执行
3
Repo 地址:github.com/vanna-ai/vanna
4 PatentWriterAgent 专利写作智能体 目前开源处于早期阶段,可以试用或者参考workflow设计 Repo 地址:github.com/ninehills/PatentWriterAgent
5 微舆 近期会支持一键部署体验,有兴趣可关注repo更新
多Agent舆情分析助手,支持全自动分析 国内外30+主流社媒 与 数百万条大众评论。
▪ Insight Agent 私有数据库挖掘:私有舆情数据库深度分析AI代理
▪ Media Agent 多模态内容分析:具备强大多模态能力的AI代理
▪ Query Agent 精准信息搜索:具备国内外网页搜索能力的AI代理
▪ Report Agent 智能报告生成:内置模板的多轮报告生成AI代理
6
Repo 地址:github.com/666ghj/BettaFish
7 HivisionIDPhotos 一套完善的AI模型工作流程,实现对多种用户拍照场景的识别、抠图与证件照生成。
▪ 轻量级抠图(纯离线,仅需 CPU 即可快速推理)
8
▪ 根据不同尺寸规格生成不同的标准证件照、六寸排版照
9
▪ 支持 纯离线 或 端云 推理
10
▪ 美颜等
11
Repo 地址:github.com/Zeyi-Lin/HivisionIDPhotos` - ```markdown
2025W44 AI大模型领域精选热点 🔥
1. OpenAI
山姆奥特曼最近播客访谈中透漏内部目标:到 2026 年 9 月,要搞出一个“AI 科研实习生”,它得能在几十万块 GPU 上跑起来;到 2028 年 3 月,要搞出一个真正的“自动化 AI 研究员”。
▪ 推出安全模型 GPT-OSS-Safeguard-20B 和 GPT-OSS-Safeguard-120B 基于之前GPT-OSS 微调的。支持自定义安全策略(写在 prompt 里面),然后模型会判断是否符合,输出思考过程,然后输出安全等级分类。 原文地址:openai.com/index/introducing-gpt-oss-safeguard/
▪ 推出 Aardvark 一款由 GPT-5 驱动的自主安全研究员(agentic security researcher),内部已投入使用。其目标是帮助开发者和安全团队自动化发现与修复软件漏洞。工作原理是监控代码库的提交和变更,识别漏洞及其可能的利用方式,并提出修复方案。Aardvark 不依赖模糊测试或软件成分分析等传统程序分析技术,而是利用 LLM 驱动的推理和工具来理解代码行为并识别漏洞。Aardvark 查找漏洞的方式与人类安全研究人员类似:阅读代码、分析代码、编写和运行测试、使用工具等等。可与 GitHub、Codex 集成 原文地址:openai.com/index/introducing-aardvark/
▪ OpenAI 已完成资本重组,通过设立非营利性基金会控制新的营利性子公司,使微软(持股27%)、基金会(持股26%)及其他方共同持股,并延长微软知识产权权益至2032年,同时重组满足了软银投资条件且与州监管机构就AGI验证及风险缓解等要求达成一致。 原文地址:techcrunch.com/2025/10/28/openai-completes-its-for-profit-recapitalization
▪ Policy更新:ChatGPT 禁止提供专业医疗、法律和财务建议。 原文地址:openai.com/ja-JP/policies/usage-policies/?utm_source=chatgpt.com
2. Kimi
与Qwen3-Next-80B-A3B类似路线,采用 KimiLinear 一种混合线性注意力架构,目标破除“二次方诅咒”
▪ Kimi 团队最新发布 Kimi-Linear-48B-A3B 系列模型,采用混合注意力策略,将轻量级线性注意力与重型全注意力结合,比例为3:1。其创新点在于引入“Delta Attention”机制的改进版本Kimi Delta Attention(KDA)和多头潜在注意力(multi-head latent attention),在保持准确率的同时,实现了75%缓存减少和高达6倍的解码速度提升。 模型地址:huggingface.co/collections/moonshotai/kimi-linear-a3b 论文地址:arxiv.org/pdf/2510.26692
▪ 据传 K3 年底发布
▪ 同样是破除“二次方”算力限制,DeepSeek-V3.2-Exp 采用Sparse Attention(一种稀疏注意力机制),孰好孰高可参考 《DeepSeek-V3.2-Exp 和 Qwen3-Next 哪个才是未来? - 知乎》 https://www.zhihu.com/question/1956137082197083536
3. MiniMax M2
与Deepseek Kimi Qwen 不同,MiniMax M2 却回归传统全注意力,不失真不省算力
▪ MiniMax M2 230B参数激活参数10B,专为 Agent 和代码而生,仅 Claude Sonnet 8% 价格,2倍速度,限时免费! 原文地址:minimaxi.com/news/minimax-m2 模型地址:huggingface.co/MiniMaxAI/MiniMax-M2
▪ 最强 Voice Agent MiniMax Speech 2.6 发布(效果很棒),全面支持 40 种全球广泛使用的语言。
▪ speech-2.6-hd 超低延时(端到端延迟低于250毫秒),归一化升级,更高自然度
▪ speech-2.6-turbo 极速版,更快更优惠,更适用于语音聊天和数字人场景
▪
原文地址:minimaxi.com/news/minimax-speech-26 体验地址:minimaxi.com/audio
4. GTC 2025
▪ Nvidia NVQLink,专为 GPU 与量子处理器(QPU)设计的互联架构,“量子与经典计算融合的里程碑”。目标是打通量子计算与 GPU 加速计算之间的隔阂。
1 过去,量子芯片通常需要通过传统 CPU 或中间控制系统与 GPU 通信,导致数据往返延迟高、误差率大、同步效率低。
2 NVQLink 提供一条高速、低延迟的硬件互联通道,使 GPU 可以直接访问量子处理器的数据通路,实现纳秒级同步与反馈。
3 NVQLink 让两者首次可以在同一台超级计算机中实现实时通信与数据共享,真正构建出量子-经典混合计算架构(Hybrid Quantum-Classical Computing)。
▪
▪ 6G信号塔 = 微型 AI 超算 未来每一座 6G 信号塔,都可能成为一台具备自学习能力与算力的“微型 AI 超算”。
1 英伟达宣布投资 10 亿美元入股诺基亚(Nokia),并联合推动 AI 原生 6G 网络 的建设。
2 5G 时代的通信网络仍以“数据传输”为核心,而英伟达与诺基亚希望在 6G 时代彻底改变这一逻辑——让“通信网络本身具备智能”。两家公司计划打造一种全新的网络架构,让基站不仅仅是信号中继,而是可以直接运行 AI 模型、执行推理任务、实时优化信号与能耗的“边缘智能节点”。
3 技术核心:英伟达新推出的 Aerial RAN Computer(ARC) 架构。它是一种面向无线接入网(RAN)的 AI 计算平台,将 GPU、网络处理单元(DPU)与软件堆栈整合在一起。借助 ARC,运营商可以在每一个基站节点上运行 AI 算法,实现以下能力: 1)实时优化信号覆盖与用户体验。 2)动态调度算力,显著降低能耗。 3)直接在边缘节点完成 AI 推理,无需回传至云端。
▪
▪ 全球最强 AI 超级计算机 英伟达宣布与 美国能源部(DOE) 和 甲骨文(Oracle) 展开战略合作,联合建设 7 台全球最强 AI 超级计算机。
将部署在美国能源部旗下的多家国家实验室,包括阿贡(Argonne)、橡树岭(Oak Ridge)等,旨在支持科学研究、AI 模型训练、气候模拟、核聚变研究、药物开发等高算力任务。英伟达称,这些系统不仅是科研设施,更是未来“AI 工厂”的原型。 其中两台最具代表性的超级计算机分别是:
▪ Solstice —— 由美国能源部与甲骨文联合建设,配备超过 10 万块 NVIDIA Blackwell GPU,是目前规划中规模最大的 AI 训练平台,目标是实现 2000+ ExaFLOPS(AI 运算模式下)性能。
▪ Equinox —— 同样基于 Blackwell GPU 架构,配备约 1 万块 GPU,计划于 2026 年上半年上线,用于能源科学与国防技术研究。
▪ - saka 老师前几周分享的这篇文章 https://skoredin.pro/blog/golang/cpu-cache-friendly-go 非常有意思,我虽然日常在 pahole 输出里看到 cacheline,但对其如何影响程序运行的理解也非常模糊。
不过更有意思的是,我已经见到三位工程师在 AI 的辅助下试图测试 “cacheline padding 带来六倍性能提升” 却没有成功,最后吐槽这是一篇错文、AI文。这里有一个有趣的知识屏障,如果不理解 cacheline 在何时会影响性能,那就可能无法写出正确的测试程序;但无法写出正确的测试程序又无法理解 cacheline 如何影响性能,知识死锁了。
你以为我想说原文的 “cacheline导致六倍性能差距” 的结论是正确的?不,那是错误的有前提条件的,并非通用结论
这些对我也是新知识,水平有限,施工区域谨慎阅读
我的测试代码不用很多工程师和 AI 用的 go bench 方法,因为抽象程度太高了,在这种性能施工区最好就写一眼能看穿汇编的简单代码。package main import ( "fmt" "os" "sync" "sync/atomic" "time" ) const N = 100_000_000 type Counters interface { Inc(idx int) AtomicInc(idx int) Result(idx int) uint64 } type unpaddingCounters [8]uint64 func (u *unpaddingCounters) Inc(idx int) { u[idx]++ } func (u *unpaddingCounters) AtomicInc(idx int) { atomic.AddUint64(&u[idx], 1) } func (u *unpaddingCounters) Result(idx int) uint64 { return u[idx] } type paddingCounter struct { val uint64 _ [56]byte } type PaddingCounters [8]paddingCounter func (p *PaddingCounters) Inc(idx int) { p[idx].val++ } func (p *PaddingCounters) AtomicInc(idx int) { atomic.AddUint64(&p[idx].val, 1) } func (p *PaddingCounters) Result(idx int) uint64 { return p[idx].val } func main() { var counters Counters if os.Args[1] == "pad" { counters = &PaddingCounters{} } else { counters = &unpaddingCounters{} } var inc func(idx int) if os.Args[2] == "atom" { inc = counters.AtomicInc } else { inc = counters.Inc } start := time.Now() var wg sync.WaitGroup for i := 0; i < 8; i++ { wg.Add(1) go func() { defer wg.Done() for j := 0; j < N; j++ { inc(i) } }() } wg.Wait() fmt.Printf("Duration: %v ", time.Since(start)) for i := 0; i < 8; i++ { fmt.Printf("Counter[%d]=%d ", i, counters.Result(i)) } fmt.Println() }
提供了两套变式, 通过命令行的 arg1 和 arg2 指定是否 padding 和是否用 atomic.AddUint64。
我本地的 cpu 0,1 是同一个核心,1,2 是不同核心,所以测试命令是taskset -c 1,2 perf stat -d -- env GOMAXPROCS=2 ./go_cpu_perf pad atom
很多细节我依然在学习中,目前可以公开的情报是:(+表示前者性能更好,-反之)
1. "pad atom" vs "nopad atom": +7.3倍性能
2. "pad nonatom" vs "nopad noatom": +3.3倍
3. "pad atom" vs "pad noatom": -2.5倍
4. "nopad atom" vs "nopad noatom": -5倍
可以看到 atom (lock prefix insn)本身就造成大量的性能影响,而 pad 会进一步加重 cacheline false sharing 导致更极端的性能差距。原文里的六倍性能差距是在 atom + pad 的场景下的测试结果,但我觉得大部分场景根本不会这么极端。
核心绑定情况也会造成很大影响。如果绑核改为 0,1 cpu,它们是同一 core,测试结果是:
1. "pad atom" vs "nopad atom": +1.75
2. "pad noatom" vs "nopad noatom": +1.65
3. "pad atom" vs "pad noatom": -1.9
4. "nopad atom" vs "nopad noatom": -2.0
在这些测试里,经典的 perf topdown 方法在 L2->L3->L4 几乎完全失效,经常会看到 L2 的 tma_core_bound 40% 然后 tma_core_bound_group breakdown 是 0%、L3 的 tma_l3_bound 15% 然而 L4 的 tma_l3_bound_group 里面四个 0%。我的 cpu 型号是 x86 meteorlake,仔细看了 pmu metrics 定义之后我觉得这就是设计上的问题,L2 再往下没有保证,只能靠微指令法师的经验来跳跃性猜测和验证。
可以确定有用的 metrics 是
- tma_store_fwd_blk: atom vs noatom 性能差距的罪魁,lock prefix insn 阻止了 store forwarding (CSAPP $4.5.5.2) 导致性能大幅下降
- tma_false_sharing: cacheline 在多核心上共享时的 race。原文其实主要就是在讨论这个讨论的性能问题。
- tma_l3_bound: snoop hitm 的间接指标。
- L1-dcache-loads,L1-dcache-load-misses: cacheline racing 的间接指标。但由于 l1 miss 至少包含了 "cacheline 不在 L1" 和 "cacheline 在 L1 但是失效",这个 miss 率其实很容易误导。
如何从 metrics 找到源码:
perf list 文档写得不全,直接看内核里的 pmu-events/.../mtl-metrics.json,比如说 perf record -M tma_false_sharing 很高,json 文件里这一项的 PublicDescription 就会写Sample with: OCR.DEMAND_RFO.L3_HIT.SNOOP_HITM
然后采样perf record -F9999 -g -e OCR.DEMAND_RFO.L3_HIT.SNOOP_HITM
然后可以可以画火焰图和栈回溯,但我现在喜欢 perf annotate -l --stdio 直接看指令0.42 : 4949aa: inc %rcx : 42 inc(i) 87.08 : 4949ad: mov 0x18(%rsp),%rax
看到 87% 的 false sharing 都是由于 inc %rcx 导致的。
讲完方法论终于可以回到主题了,cacheline 如何影响性能:如果是一个线程共享数据 A 在多核上并行 ++,核心1 修改了 A,那么核心2 的 L1 缓存的包含 A 的 cacheline 就会失效,这就是 false sharing。对于共享数据 A 来说这不可避免,但是如果有另一个 独立 数据 B 和 A 在同一个 cacheline,那么 A 在多核上刷存在感就会导致 B 的 L1 cache 失效,尽管 B 可能完全是一个单线程非共享数据。好的 cacheline 设计可以加上一段 padding 把 B 强制隔离出 A 所在的 cacheline,这样 A 刷新 cacheline 不会导致 B 的 cacheline 失效。
这些知识真的非常晦涩难懂,资料很少,AI 基本在帮倒忙,我感觉像是在星际航行,目睹所有令人惊叹的宇宙奇观,恍惚间就化入无穷。 - #人工智能
谢青池,美团光年之外的产品负责人,用了一年多的时间一篇一篇地啃完了200多篇AI论文,从开始全然不得要领,到后来逐渐地入门,而他希望将他的论文探索之旅开源给大家。
正因为他是产品经理,也许他的讲解能更通俗地带领我们一窥“技术之美”。
《AI演义 36篇论文开启你的探索之旅》 - 对于所有对数据基础设施感兴趣、想快速了解大数据如何运作、数据系统是如何设计的,以及其中有哪些权衡的人,都建议看看这一份来自 xiangpeng 的分享,非常赞!基本上覆盖了数据系统绝大部分主题,非常好的入门!
https://intro-data-system.xiangpeng.systems -
- 我说说我的看法:
1. 对于大多数小公司(甚至大公司)业务服务基本都是无状态的(任何时候都应该尽力避免有状态服务),所以部署啥的遇到最多的就是Deployment Service ConfigMap Secret env,并且第一次发布套模板后续发布基本都是只改配置和镜像版本号
2. 入口域名购买云厂商lb服务绑定后ingress controller也是点击就送,入口网关解决了,后续增加二级域名路由只需要绑定service就行,甚至是傻瓜下拉框的
3. 完成这两步你得到了什么呢?a. 崩溃重启 b.点击扩容甚至HPA c.服务发现 d.配置中心密钥存储 e.基本的容器监控告警 f.入口网关及域名证书管理 g.随意加机器 h.滚动发布,金丝雀灰度
4. 如果你愿意再投入一点点,会发现甚至可观测性log metrics traces 也是点击就送的,log部署loki operator,metrics部署prometheus operator,traces部署jeager operator,这些所谓复杂的需要helm部署的其实被云厂商做成软件商店了(不过追求稳定可以直接买云服务,我们当初小团队都是自己部署的)
5. 我们结合第一点,需要CICD提效发现常规发布改动点太少了,所以你甚至可以用最土的方式脚本替换yaml模板变量的方式做发布,根本不需要helm rancher之类的
6. 最后再说一句,复杂的有状态场景例如搭db之类是因为本身就复杂而不是k8s,不用k8s只是给大家一种自己搞定了的错觉而已 - “学术论文科普”提示词,把枯燥的学术论文变成通俗易懂的科普文。
注意:Gemini 2.5 Pro 效果最佳
---- 提示词开始 ----
你是一位顶尖的科普作家和知识转述者,被誉为“最会搭梯子的人”。你的专长是将那些充斥着术语、数据和复杂模型的学术论文,转译(Reframe)成普通大众能轻松读懂、产生共鸣并深受启发的科普文章。
你的使命不是“翻译”论文,而是“重建”理解。你为读者搭建一座从“一无所知”到“原来如此”的桥梁,让他们在零负担的阅读中,领略到科学研究的真正魅力、核心发现及其对现实世界的意义。
---
工作流程:从论文到科普的“阶梯搭建”
当你收到一篇需要进行科普解读的学术论文时,你将严格遵循以下步骤:
* 第一步:挖掘“人”与“动机” (The "Who" and "Why")
* 在深入论文细节前,先检索作者及其所属机构的背景。
* 尝试建立一个有趣的联系:为什么是“他们”在研究“这个”问题?
(例如:这个实验室是否一直在该领域深耕?他们是不是“跨界”解决了一个老问题?或者这个机构的使命是否与此相关?)
* 【应用规则】:如果背景故事(如作者的“执念”或机构的“使命”)能让研究动机更生动,就在文章中巧妙融入。
如果联系牵强,则不必在正文中提及,避免生硬介绍。
* 第二步:钻研与消化 (Digest and Understand)
* 深入阅读论文,彻底拆解其核心三要素:
1. 研究问题 (The Question):他们到底想解决什么谜题?这个问题的背景和重要性是什么?
2. 研究方法 (The How):他们是怎么找到答案的?(重点理解其思路,而非复述技术细节)
3. 核心发现 (The Finding):他们最终发现了什么?这个发现有多“反直觉”或多“重要”?
* 第三步:定位“行业坐标”与“Aha!时刻” (Locate its Position and the "Aha! Moment")
* (必要时使用工具检索)结合业界或学术界的现状来分析这篇论文。
* 它在整个领域中扮演了什么角色?是解决了同行一个“老大难”的痛点?是推翻了一个旧认知?还是开辟了一个全新的赛道?
* 提炼“故事线”:将论文的“论证逻辑”转化为“叙事逻辑”。
找到论文中最激动人心的“Aha!”时刻,并明确这篇科普文章的核心“卖点”(Takeaway)——读者读完后,能带走的那个最清晰、最有价值的知识点。
* 第四步:撰写科普博文 (Compose the Pop-Science Blog)
* 完全代入下方定义的“角色定位”与“写作风格”,撰写一篇独立、完整、引人入胜的科普解读。
* 注意:篇幅长度不限,以“把普通人彻底讲明白”为唯一标准。
* 确保在“所以呢?” (The "So What?") 部分,有力地传达出它对行业或普通人的真正影响(基于第三步的分析)。
---
读者与风格
* 目标读者:对世界充满好奇的普通大众。他们没有专业背景,渴望理解新知识,但对术语和公式天然“过敏”。他们阅读的目的是获取新知、满足好奇心和“哇塞”的瞬间。
* 写作风格:
* 极致通俗 (Radical Accessibility):比喻是你的第一语言。能用“厨房里的化学反应”解释的,绝不用“非对映选择性”。如果必须使用术语,必须立刻用一个生动的类比将其“翻译”掉。
* 故事为王 (Storytelling):把研究过程讲成一个“破案故事”或“探险之旅”。科学家是主角,他们面临一个难题,设计了一个聪明的“陷阱”(实验),最后抓住了“真相”(结论)。
* 聚焦“所以呢?” (The "So What?"):时刻帮读者回答这个问题。这个研究跟我有什么关系?它为什么重要?它可能如何改变我们的生活或认知?
* 简化而不歪曲 (Simplify, Don't Misrepresent):这是科普的底线。在简化复杂概念时,保持核心事实的准确性。清晰地区分“已证实的”和“推测的”。
---
写作思路与技巧(供自由使用)
* 开篇点题,建立框架:
* 可以用一个生动的问题、反直觉的观察或核心冲突来引入主题,快速帮读者定位。
* 也可以先用简洁的语言勾勒出原文要解决的核心问题或讨论范围。
* 结构化梳理,逐层解析:
* 善用小标题或清晰的段落划分,引导读者逐步理解。
* 在转述原文观点时,无缝融入类比,让复杂的点变得具体可感。(例如:“作者提到的‘异步通信’,你就可以理解为发邮件,而不是打电话。”)
* 聚焦重点,详略得当:
* 明确区分主干与枝叶。重点阐释核心观点与关键逻辑,简略带过次要信息。
* 确保读者高效抓住重点。
* 巧妙融入背景:
* 如果原文涉及人物或机构背景,自然融入解读,帮助读者理解“为什么”或“此刻的重要性”,避免生硬介绍。
* 结尾总结,提供价值:
* 清晰提炼原文核心价值,或指出其当下意义。
* 给读者一个明确的Takeaway,让他们确实学到东西,理解原文。
---
禁止出现的表达方式
* 避免生硬的引导语,如“本文研究了……”、“该论文的作者发现……”、“实验结果表明……”。
* 严禁直接复制论文摘要或引言中的学术黑话。
* 避免罗列枯燥数据或统计指标(如p值、置信区间),除非能转译为“有多大把握”或“效果有多明显”。
---
核心目标
你的文字是读者通往科学殿堂的“快速通道”和“专属翻译器”。
你必须用最大的真诚和智慧,将学术的“硬核”包裹在通俗、有趣、有故事性的“糖衣”里,让读者在愉快的阅读中,毫不费力地吸收最前沿的知识精髓。