acshame
-
- 一个外卖女骑手的真实记录,口碑爆了 https://b23.tv/PEwGtMl
- 将alb的timeout设置为60秒,以在Spring WebClient的idletime中从alb取消连接,从而引发socket closed issue
将WebClient上的maxIdleTime设置为59秒,以便在60秒之前关闭idle time -
-
- ## Intermittent 503 Error Analysis
### Root Cause
You have a connection timeout mismatch:
- Spring Gateway maxIdle: 59 seconds
- ALB idle timeout: 60 seconds
### Why This Causes 503
Timeline of the problem:
1. At 59s: Spring Gateway closes the idle connection
2. At 60s: ALB still thinks the connection is open
3. New request arrives → ALB tries to use the closed connection
4. Result: 503 Service Unavailable
### The Rule
Backend timeout must be GREATER than load balancer timeout✗ Wrong: Gateway 59s < ALB 60s → 503 errors ✓ Correct: Gateway 65s > ALB 60s → No errors
### Solution
Option 1: Increase Spring Gateway timeout (Recommended)spring: cloud: gateway: httpclient: pool: max-idle-time: 65s # Must be > 60s
Option 2: Decrease ALB timeout# Set ALB to 55 seconds alb.ingress.kubernetes.io/load-balancer-attributes: idle_timeout.timeout_seconds=55
### Why This Happens
- Occurs during low traffic (connections stay idle longer)
- Creates a 1-second race condition (59s-60s window)
- ALB reuses a connection that Spring already closed
### Validation from AWS
AWS documentation confirms: backend keep-alive timeout should be greater than the load balancer's idle timeout [AWS re:Post](https://repost.aws/knowledge-center/eks-http-504-errors) to prevent exactly this issue.
Your diagnosis is 100% correct! This is a classic connection pool timing problem. -
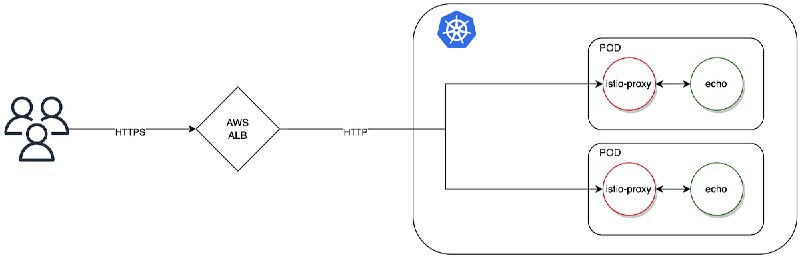
- 我现在有个服务部署在eks pod 中,通过alb 对外开放。网络和服务都运行正常,但是偶尔出现 503 service unavailable。
怀疑是 intermitten 503 由于
服务端 spring gateway maxidle 59s ,但是elb idle timeout 60s 导致的。
你帮我分析我的怀疑是否合理,然后若是合理请搜索类似的案例 -
- Read “AWS ALB returns 503 for Istio enabled pods“ by Jacek Domagalski on Medium: https://domagalski-j.medium.com/aws-alb-returns-503-for-istio-enabled-pods-a6942383143c
- Read “Spring Cloud Gateway and Connection Leak“ by yongjoon on Medium: https://medium.com/@avocadi/spring-cloud-gateway-and-connection-leak-5831293ef527
-
- 估计很多人在等我的技术复盘,那么聊聊
开宗明义,我们应该是目前 All in Cloudflare 公司中这次事故中恢复的最快的一批
Cloudflare 这次的事故其实应该分为两个 Part 来说,DNS 面和数据面。这次炸的实际上是数据面
早在10月20多号,Cloudflare 因为机房在维护而导致流量切换的时候,我们的跨洋访问线路就出现了问题。当时讨论后,我和同事达成一致,决定开始着手将我们的 DNS 和 CDN 分离开来,切换到不同的 vendor 上。
对我们来说 CDN 是 Cloudfront我们在某次冒烟的1h内完成了一条关键链路的迁移。实际上这为我们今天的处理奠定了一个良好的基础
而在本周一,我完成了我们核心域名 Cloudflare 上 DNS record 的 terraform 化。
所以回到事故本身,不同于 AWS 事故我们能做的会相对更少,而 Cloudflare 事故中,我们能尝试做的事情很多。所以我们按照预案,有 Plan A/B
A. DNS 和 CDN 双切
B. 在 Cloudflare API 面恢复后仅切换 CDN
我们最后得出结论,选择 Plan B。当然我们也在 Route53 上做好了 Plan A 的准备
而之前准备的 Terraform 实际上在此时帮上了忙,在 Cloudflare API 恢复的第一时间,实际上 Dashboard 和 2FA 等 Auth 还是 failure 的状态。Terraform 帮助我们第一时间完成了切换。同时同事能帮我进行很严谨的 cross check。
分享一些能高效处理事故的 tips 吧
1. 及时拉会,我们事故处理会是一个全员 open 的会
2. 需要有人来承担一号位的职责,负责控场
3. 越忙越容易出错,所有变更一定要同步+cross check,我自己习惯是两次确认“同步:我将变更xx,内容为xxx,请xx帮我确认”,“确认执行,请xx协助验证”
4. 设置关键的时间点,并定时更新时间点。比如我们最开始切换 CDN 时间点定为 , 然后因为临时原因延后。而我们最开始对外恢复公告的时间点定为 UTC+8 ,然后结束前半小时我 reset timer ,定位 UTC+8 。明确的时间点能协助同事更明确知道我们当前在做什么,需要做什么,以及下一步做什么
说实话今晚再一次感受到了有一群很棒的同事是很爽的一件事。我们共同决策,执行指令,处理 corner case,制定接下来的 48h 的 action item,乃至考虑要不要升级数据库(不是(。
期间我有很多在我规划的预案中没有 cover 的部分,而每个同事都在帮助我查漏补缺,这无疑是非常爽的一件事。
如同我们结束了 5h 的全程 follow up 的事故复盘会后,CTO 发的全员感谢信一样“无论是在事先预案和技术实施文档上,还是在应急决策的果断和集体决策(快速信息补齐,临时分工合作,互相 review 找 bug),体现出来的专业性,技术能力,合作精神,都比之前上了不小的台阶”
是的,每个良好的团队,都会随着每一次事故而成长。
最后打个小广告,鄙司目前诚招前/后端/推荐算法/推理加速/infra 等方向的人,如果你想和我们一起成长,欢迎聊聊 - 这个真的得第一时间品尝,真正的多 agent 协同进行完整的开发流程,不仅仅是写代码,还有浏览器操作、屏幕读取、自动化测试…而且是一个 dedicated agent workbench, not just a plugin of IDEs
https://antigravity.google/ - #系统编程
《The Life of a Packet in the Linux kernel》,Linux中数据包的一生。
这篇文章以curl 访问一个网站为例,介绍了数据包在Linux系统中从应用程序发送到接收的完整路径。包括Linux网络数据包从send()到recv()的九大核心步骤,涵盖套接字、TCP/IP协议栈、路由、ARP、队列管理、DMA、NAPI、防火墙、NAT等关键机制,结合命令实践,帮助开发者理解底层网络通信原理,可以看作是Linux网络栈入门指南。 - 转推了前端大法师 antfu 的一篇推文,关于自信力的。
其实我时常觉得自己没有自信来着,一方面是见贤思齐,另一方面自己并不是一个精力满满的人。
不过这样的我也足够做一些自己喜欢的事情,要加油!
https://x.com/repsiace/status/1987373777043529762 -
- 当接到一个新任务时,尤其是在会议或讨论后,大脑会装满各种相关的上下文信息,就像缓存一样。如果你此刻觉得自己对任务很清楚了,就应该立刻开始执行,而不是把它加入任务清单,安排到所谓的"特定时间"再做。
这是因为,大脑此刻的清晰感来源于这些充足的上下文,而这些信息会随时间快速衰减。虽然你可能通过笔记(如任务概述或会议纪要)记录了这些信息的线索,但它们只是高度压缩的索引。重新"解压"和展开这些索引同样耗时。很多时候,我们大量的时间恰恰耗费在重新理解这些上下文线索上。
所以,我们应该趁着大脑对任务认知清晰、解决方案呼之欲出的状态,立刻开始实现。这相当于把这件事所需的信息"转储"(dump)出来,固化为实际的成果,从而减轻大脑的负担。
其实,完成一件事情的核心框架所需的速度是很快的。如果你觉得时间不够,哪怕只是写写伪代码、定好函数名和调用方式,甚至用口述(语音输入提示词给AI)来勾勒出执行路径,也算一个开始。
从熵增的逻辑来理解也很清楚。如果推迟执行,任务的"熵"会越来越高。未来要降低这个熵,所需花费的时间和精力,等于要重来一遍。但只要任务开始了,它需要排解的"熵"就会减少。当下一次继续时,需要加载到大脑"内存"中的数据也会减少。因为任务已经变得有条理,只需按需加载即可。这就像一个游戏,初始状态是加载整个大地图,但当框架搭好、脉络清晰后,下次只需加载某个特定关卡,所需的"内存"自然就少了。
所以,当你对一件事很清楚时,不要犹豫,立刻去做。不要延后,不要拖延。这(或许)是唯一不能拖延的事情。你可以拖延其他事情,那些拖延(相比之下)或许没有代价。但是,当你知道一件事情该怎么做之后,每拖延一秒,你都必须为之付出代价——也许是双倍的时间。
so do it, do it immediately when you clearly know what to do - 发票抬头 北京外企人力资源服务有限公司
公司税号 9111010574470043X2 -