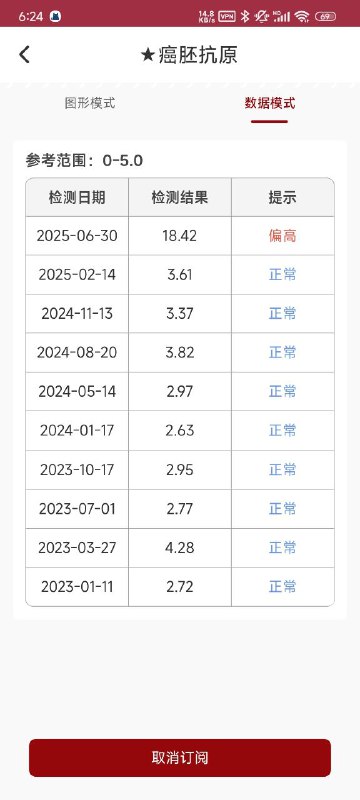
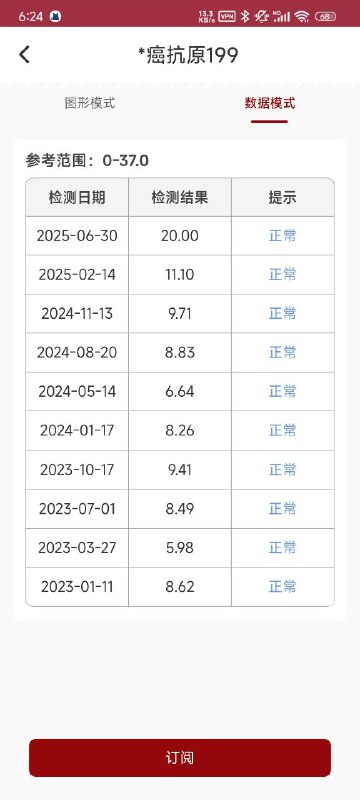
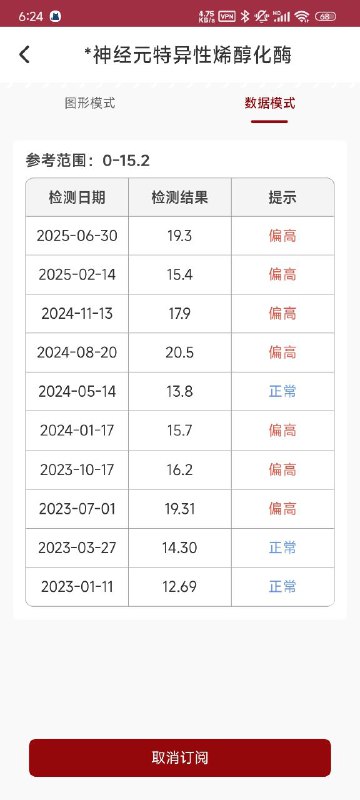
// 1. 创建约束
CREATE CONSTRAINT job_id_unique FOR (j:Job) REQUIRE
j.id IS UNIQUE;
CREATE CONSTRAINT pipeline_id_unique FOR (p:Pipeline) REQUIRE
p.id IS UNIQUE;
CREATE CONSTRAINT datasource_id_unique FOR (d:DataSource) REQUIRE
d.id IS UNIQUE;
// 2. 创建16个数据源
WITH ['MySQL', 'Kafka', 'HDFS', 'S3', 'PostgreSQL', 'Oracle', 'MongoDB', 'Cassandra'] AS dbTypes
UNWIND range(1, 16) AS id
CREATE (:DataSource {
id: id,
name: 'DataSource_' + id,
type: dbTypes[id % size(dbTypes)],
create_time: datetime()
});
// 3. 创建28条流水线
UNWIND range(1, 28) AS id
CREATE (:Pipeline {
id: id,
name: 'Pipeline_' + id,
description: 'ETL processing flow ' + id
});
// 4. 创建100个作业并关联流水线
UNWIND range(1, 100) AS jobId
CREATE (j:Job {
id: jobId,
name: 'Job_' + jobId,
status: ['RUNNING', 'SUCCESS', 'FAILED', 'PENDING'][toInteger(rand() * 4)],
expected_start: datetime() + duration({minutes: toInteger(rand() * 120)}),
expected_end: datetime() + duration({minutes: toInteger(120 + rand() * 180)}),
create_time: datetime()
})
WITH j, jobId
// 随机分配到流水线
WITH j, toInteger(rand() * 28) + 1 AS pipelineId
MATCH (p:Pipeline {id: pipelineId})
CREATE (j)-[:IN_PIPELINE]->(p);
// 5. 建立作业依赖关系
// 创建依赖关系(确保无环)
WITH 100 AS jobCount
UNWIND range(1, jobCount) AS jobId
MATCH (current:Job {id: jobId})
// 每个作业有0-3个依赖
WITH current, toInteger(rand() * 3) AS dependencyCount
CALL {
WITH current, dependencyCount
UNWIND range(1, dependencyCount) AS _
MATCH (dependee:Job)
WHERE
dependee.id <
current.id // 确保只依赖前面的作业(避免循环)
RETURN dependee ORDER BY rand() LIMIT 1
}
CREATE (current)-[:DEPENDS_ON]->(dependee);
// 6. 关联作业与数据源 (最终修复方案)
MATCH (j:Job)
// 为每个作业生成随机数量的数据源关联 (1-3个)
WITH j, toInteger(rand() * 3) + 1 AS sourceCount
// 创建0-15的随机序列
UNWIND range(0, 15) AS sourceIndex
WITH j, sourceCount, sourceIndex
// 随机排序数据源索引
ORDER BY rand()
// 只取前 sourceCount 个
WITH j, sourceCount, collect(sourceIndex) AS shuffledIndexes
WITH j, shuffledIndexes[0..sourceCount] AS selectedIndexes
UNWIND selectedIndexes AS idx
// 获取实际数据源
MATCH (d:DataSource {id: idx + 1})
CREATE (j)-[:CONSUMES]->(d);